
Lors d’une journée chez Microsoft, j’ai pu découvrir quelques une des nouveautés de SQL2012. Outre Reporting Services, Click View, les rôles et la sécurité ou encore les nouveaux types de cubes, il y a aussi quelques nouveautés dans la syntaxe du moteur de bases de données. Je vous parlerai ensuite de “Always ON” qui est la nouveauté de la haute disponibilité.
Nouvelles syntaxes dans SQL 2012
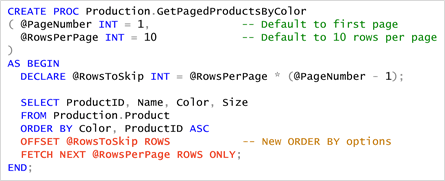
Offset
Offset permet de paginer les résultats depuis un record et un nombre de records.
c’est une séquence pour définir des pas différents suivant le cas. C’est très utilisé dans une seule table avec une clé de 1 à 10000, de 5 en 5, pour une première tranche d’enregistrements, et un incrément de 10 en 10 pour les enregistrements de 10001 à 30000 etc.
Possible de le mettre dans le create table ou directement dans le insert.

dates
Quelques nouvelles fonctions de manipulation de dates :
DATEFROMPARTS, TIMEFROMPARTS, DATETIMEFROMPARTS, DATETIME2FROMPARTS, SMALLDATETIMEFROMPARTS, DATETIMEOFFSETFROMPARTS, EOMONTH
et puis le formatage intègre maintenant la culture (c’est bien ça pour les sites web).

CONCAT
La syntaxe de CONCAT permet une concaténation avec un nombre de paramètre non définis. En plus, une valeur NULL est remplacée par un espace lors de la concaténation.
![]()
currency
Format “currency” et conversion des valeurs (même avec le rouble maintenant)

RAISE_ERROR
a été amélioré pour donner (enfin) le bon numéro de ligne même avec des procédures stockées.
Results SET
est une commande qui permet de convertir les données à la sortie comme à l’entrée. Vous assurez alors le resultat d’un select avec des types de données mais aussi lors d’un update ou d’un Insert. C’est drôlement pratique.
TRY PARSE/CATCH
pour gérer les erreurs.
PARSE (string_value AS data_type [USING culture])
TRY_PARSE(string_value AS data_type [,USING culture])
TRY_CONVERT(data_type[(length)], expression,style)

IIF et choose
Pour les amoureux d’Excel , le IIF et le choose qui permettent un if/else et équivalent if elseif, elseif en une ligne (comme dans Excel)
IIF(boolean_expression, true_value, false_value)
CHOOSE(index, value1, value2, …)

La lectures de structures de tables aussi est interessantes avec une nouvelle procédure stockée.
sp_describe_first_result_? pour retourner la structure d’une table.
sp_describe_first_result_set @tsql = N’SELECT * FROM Person.Address’
LEAD / LAG
Pour le suivant et le précédent plutôt que de faire un sub query avec un self join. Cette nouvelle syntaxe permet de baisser considérablementles temps d’exécution de cette requête.
En 2008R2, on aurait saisi cette requête :

En 2012, on écrit comme ceci :
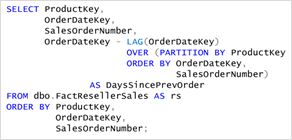
La différence vue par le query analyser est impressionnante. On passe de 99% du temps total pour subquery à 1%.
Always ON SQL 2012
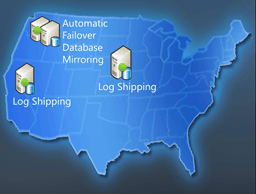
Always ON est le nom donné dans SQL 2012 pour le groupement de la haute disponibilité et la reprise d’activité en cas de souci majeur. Cela remplace les loadshipping et autres systèmes actuels de haute disponibilité.
- Pour mettre le « Always ON », il faut au moins un serveur windows 2008R2 et au moins le Framework 3.5 + installer le module « Always On » évidement.
- On peut utiliser « system center » pour piloter le “Always ON”. Toutes machines du cluster peuvent servir.
- Limitation à une protection de 4 datacenters.

Pour le failOver, on peut choisir quelles bases sont concernées et pas obligatoirement tout le serveur comme dans les versions actuelles.
La gestion de la haute disponibilité peut se faire en mode synchrone ou asynchrone.

On ne pouvait pas faire de cluster avec 2008 sans que le hard ne soit validé. En 2012, ce n’est plus le cas.
On peut également séparer les répartitions de haute disponibilité des bases indépendamment des Logs.
Le système « Always ON » est en fait piloté par un seul service, disposant de sa propre adresse IP et recevant toutes les connexions. C’est lui qui aiguille les requêtes suivant l’état des groupes de serveurs.

Avec SQL2012, les grappes de serveurs secondaires peuvent servir également en lecture. Par exemple les rapports et la lecture des cubes mais aussi les sauvegardes. Ceci allégeant alors la grappe de production en écriture et lecture.

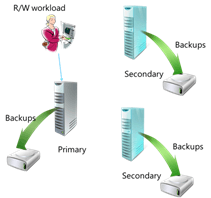
Pour mettre en œuvre ce “Always ON”, il existe un assistant. Pour les puristes, tout se fait aussi avec le Powershell.
Assistant Cluster
Choisir les serveurs de ce cluster puis Nom du cluster.
Il faut que le cluster soit “Online”. Cela se trouve dans les propriétés du serveur SQL. Il faut le faire depuis chaque serveur avec management studio ou alors en PowerShell.
On définit le nom de ce cluster puis on choisit les serveurs SQL membres. A partir du principal, on choisit les bases qui seront répliquées dans les autres. (Le backup full doit être fait auparavant pour que les bases soient accessibles dans la liste.)
On choisit le principal, le secondaires, et on définit si les reliquats sont accessibles ou s’ils sont en lecture seule.
A la fin, il demande comment synchroniser des données : tout, différence, rien. Si rien, la synchronisation se fera par backups manuellement.
Le loadshipping permettrait de faire des répliquas avec un temps de retard : 6h par exemple pour éviter des erreurs humaines.
Pour que ça marche, il faut penser qu’il faut aussi les mêmes agents, stores, etc. Attention, les jobs ne tournent que sur un serveur en même temps.
Il existe un tableau de bord de “always ON” dans management studio afin de voir, entre autre, l’état des travaux des synchronisations.
La procédure sp_server_diagnostics permet d’accéder aux diagnostiques du cluster. Avec 2008R2, ce n’était pas aussi complet.
On crée avec le “Always ON” un “listener” avec une adresse IP qui permet d’avoir un seul serveur fantôme qui représente le cluster. On peut avoir jusqu’à 64 masques réseau si les serveurs membres se trouvaient dans des réseaux d’adressage différents ! C’est ce “Listener” qui est surtout la nouveauté car il s’emploi à recevoir en un seul point les demandes de vos applications. Si le serveur principal tombait, alors ce système remettra alors les requêtes à un des serveurs secondaires.
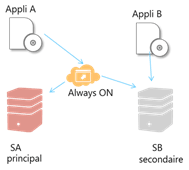
Prenons ce cas :
Un cluster avec deux grappe un SQL ‘SA’ et un SQL ‘SB’.
Mon application A discute avec le cluster.
Mon application B, en lecture discute avec le serveur ‘SB’, membre du cluster.
Le ‘SA’ tombe à l’eau, qu’est ce qui reste ? Le ‘SB’.
Mon application ‘A’ n’y voit que du feu car « Always ON » redirige les requêtes sur ‘SB’. l’application B, elle continue à discuter avec ‘SB’. Le serveur ‘SB’ est plus solliciter mais tout fonctionne bien.
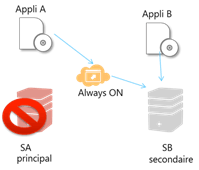
Le temps d’immobilisation de ‘SA’ va déclencher une « élection » par « alwaysON » et ‘SB’ devient le serveur principal (Le temps de déclenchement des élections est paramétrable). Une fois ‘SA’ réparé, il deviendra secondaire.
Il doit y avoir moyen de forcer une réélection. En cherchant un peu, il semble que ce soit par powershell.
Il existe un centre de ressources sur internet pour “always ON” http://www.microsoft.com/en-in/sqlserver/future-editions/mission-critical/SQL-Server-2012-high-availability.aspx
Conclusions
Les queries ont évolué mais ce n’est pas non plus une révolution. On se rend compte que le moteur SQL est mature et il n’offre donc que peu d’évolutions. Les lignes d’évolutions sont dans les additifs d’SQL comme la haute disponibilité, la reprise d’activité, mais aussi reporting services et click view.
La sécurité d’accès à SQL2012 a aussi évolué et doit se faire en créant des rôles. Rôles dans SQL server. Ce sont à travers ces rôles que les accès aux données sont filtrés mais aussi les accès aux serveurs et aux applications.
« AlwaysOn » apporte une gestion centralisée des clusters qui permet aux grandes structures d’administrer en un seul point des serveurs distants.
Les applications qui font appel à « ce » cluster de serveurs disposent alors d’une seule chaine de connexion qui n’est plus nécessaire de changer en cas de sinistre. Précédemment, il fallait changer l’adresse du serveur principal pour le secondaire. Ou adapter son DNS.
![[Interview] Martial Auroy, professionnel du monde Microsoft 2](https://www.synergeek.fr/wp-content/uploads/2020/11/martial_auroy_interview-310x165.jpg.avif)
